System architecture
hivememory is a shared memory layer that sits between agents and their LLM calls. Agents write structured artifacts after research, query memory before starting new work, and receive conflict alerts when findings disagree.
The API surface is small: write(), query(), get_conflicts(), resolve_conflict(), and export_wiki(). Everything else is internal.
The data model
The core unit of shared memory is a ReasoningArtifact — a structured claim with evidence, confidence, and provenance. Artifacts are queryable, comparable, and auditable. They replace raw text dumps.
ReasoningArtifact
- id str — UUID, auto-generated
- claim str — the factual claim this artifact represents
- agent_id str — which agent produced this
- evidence list[Evidence] — supporting evidence with source and reliability
- confidence float — 0.0 to 1.0, how confident the agent is
- dependencies list[str] — artifact IDs this builds on
- topic_embedding list[float] — sentence-transformer embedding of the claim
- created_at datetime — UTC timestamp
- status str — "active" or "superseded"
Evidence
- source str — where this evidence came from
- content str — the evidence text
- reliability float — 0.0 to 1.0
Artifacts link to each other through the dependencies field. When Agent 2 queries memory and finds Agent 1's work relevant, it lists those artifact IDs as dependencies in its own artifacts. This creates the provenance DAG.
FAISS + SQLite dual backend
hivememory uses two backends in parallel: FAISS for fast vector similarity search and SQLite for durable structured storage. Every artifact is stored in both.
Write path
When hive.write() or hive.store() is called:
- The claim text is embedded using sentence-transformers (all-MiniLM-L6-v2)
- The embedding is L2-normalized and added to the FAISS IndexFlatIP
- The full artifact (including embedding) is serialized to JSON and stored in SQLite
- Conflict detection runs against existing artifacts in the index
- The artifact is appended to the in-memory list
Query path
When hive.query() is called:
- The query text is embedded using the same model
- FAISS performs inner-product search (equivalent to cosine similarity on normalized vectors)
- Top-k artifacts are returned, ranked by similarity
query_with_scores() returns similarity scores alongside artifacts, enabling threshold-based decisions on whether to skip or augment a research call.
Two-stage contradiction pipeline
Every new artifact is checked against existing claims. The pipeline is designed for high recall at stage 1 and high precision at stage 2.
Cosine similarity filter
When a new artifact is stored, FAISS finds the top-10 most similar existing claims. If any pair has cosine similarity above the conflict_threshold (default 0.8) AND a confidence difference greater than 0.3, a conflict is flagged.
This is fast (sub-millisecond) and catches most potential contradictions. It also produces false positives — two claims can be similar without contradicting each other.
Contradiction check
Flagged pairs are sent to an LLM (OpenAI or Anthropic) with a structured prompt asking whether the claims truly contradict each other. The LLM returns a JSON verdict with is_contradiction, explanation, and winner_index.
This eliminates false positives and provides an explanation that gets stored with the resolution.
Contradiction check prompt
System: Two research findings may contradict each other.
Respond with JSON:
{"is_contradiction": true/false,
"explanation": "...",
"winner_index": 0 or 1}
User: Claim 1 [agent-id]: {claim text}
Claim 2 [agent-id]: {claim text}
Dependency DAG
Every artifact records which prior artifacts it depends on. This forms a directed acyclic graph that tracks the lineage of knowledge across agents. You can query the DAG to answer: "which agent's work did this conclusion build on?" and trace any finding back to its sources.
When an upstream artifact is superseded (e.g., its conflict was resolved against it), downstream artifacts that depended on it can be flagged for review.
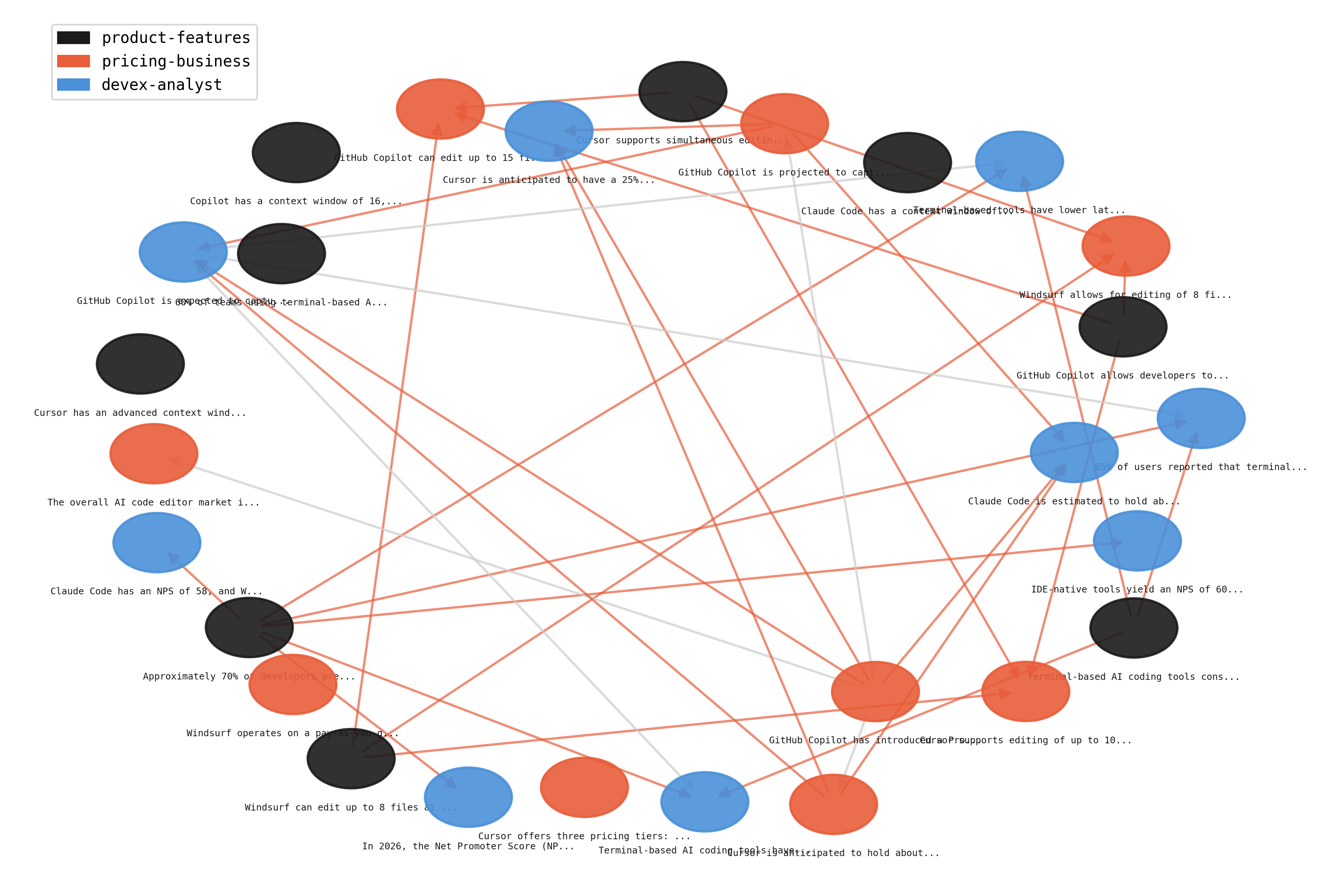
Provenance DAG from a real benchmark run. Colors indicate source agent. Edges show "built on" relationships.
Markdown knowledge base
hivememory can export the full artifact store as a set of interconnected markdown files — a wiki of everything agents have learned. The export includes an index page, per-agent topic pages, a conflicts page, and a provenance visualization.
This is inspired by single-agent knowledge base patterns (see Karpathy's work on LLM knowledge accumulation). hivememory extends this to multi-agent systems where the knowledge base is built collaboratively and contradictions are surfaced rather than silently overwritten.
from hivememory.wiki import WikiExporter
WikiExporter(hive).export("wiki_output/")
# generates: INDEX.md, CONFLICTS.md, PROVENANCE.md,
# and per-agent topic pages